
CLaRA - Apple's Compression-Native RAG
SAINTS Intelligence Brief | Edition 04x (Special) | December 07, 2025

Special Edition: Single-Paper Deep Dive
Published: December 07, 2025
arXiv: 2511.18659 | Released: November 27, 2025
Editor’s Note
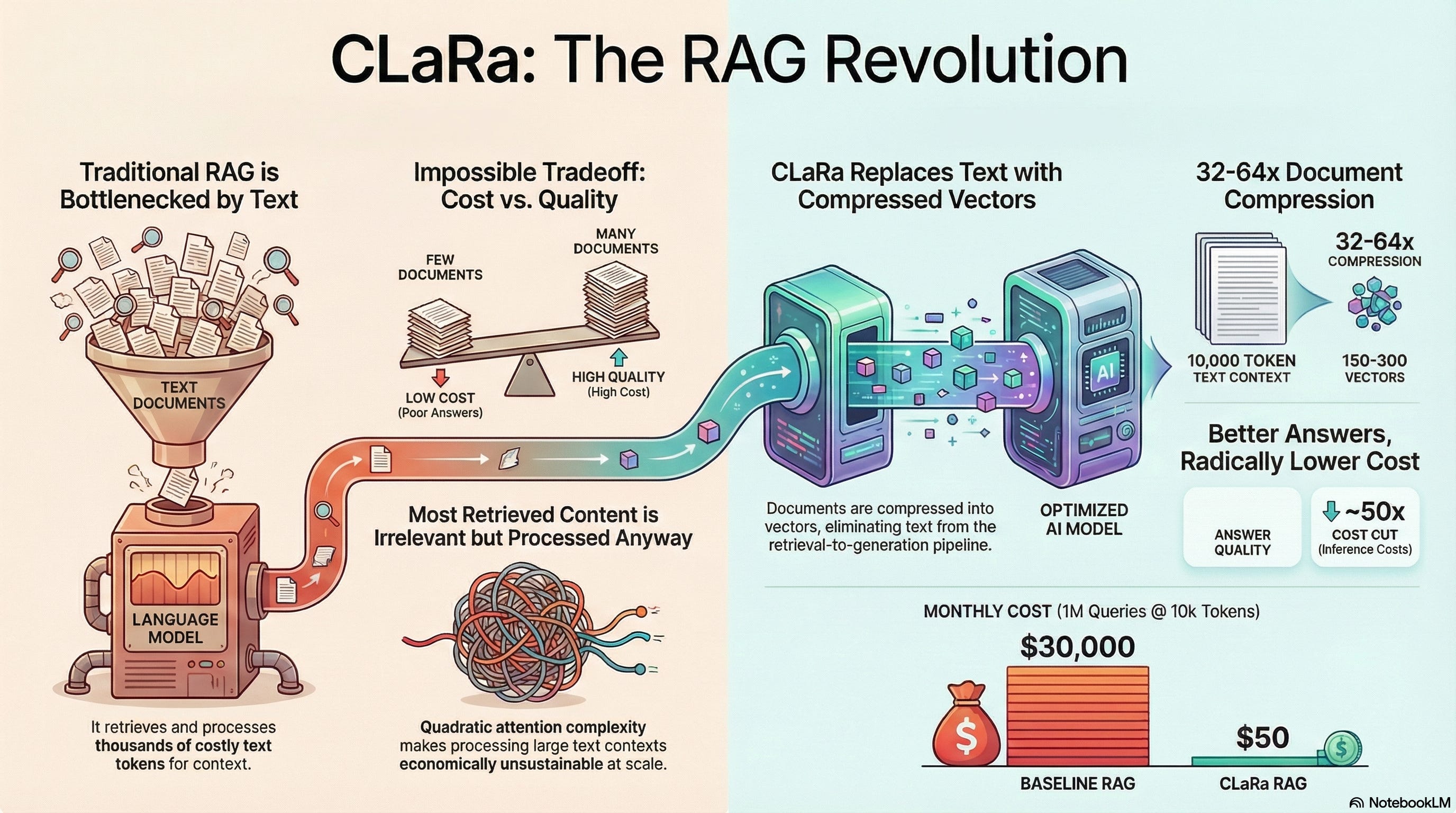
Apple’s machine learning research team has released CLaRa (Continuous Latent Reasoning), a fundamental rethinking of how retrieval-augmented generation should work. Unlike traditional RAG systems that retrieve text documents and hope the language model can extract relevant information, CLaRa operates entirely in continuous embedding space—compressing retrieved documents by 32-64× while preserving answer-critical information through joint optimization of retrieval and generation.
This special edition examines why CLaRa represents a paradigm shift for RAG deployments, particularly for resource-constrained environments where context window costs dominate inference budgets.
The RAG Context Crisis
Retrieval-augmented generation transformed how language models access knowledge:
Overcome training cutoffs by retrieving current information
Ground responses in authoritative sources
Enable private knowledge without retraining base models
Yet conventional RAG creates a new bottleneck: context length explosion.
Typical RAG workflow:
Query submitted to retrieval system
Top-k documents retrieved (k = 5-20 typical)
Full documents concatenated into LLM context
Model generates answer from megabytes of text
The problem:
5 retrieved documents @ 500 words each = 2,500 tokens of context
20 documents for complex questions = 10,000+ tokens
Context processing dominates inference cost (quadratic attention complexity)
Most retrieved content irrelevant to specific question (but model processes it all)
Result: RAG makes inference expensive and slow, undermining the efficiency advantage of retrieval over fine-tuning.
CLaRa’s Compression-Native Approach
Core Innovation: Continuous Latent Reasoning
CLaRa eliminates text from the retrieval-to-generation pipeline:
Traditional RAG: Query → Retrieve Documents → Concatenate Text → Generate Answer
CLaRa: Query → Retrieve Documents → Compress to Embeddings → Generate Answer
The shift:
Documents never converted to text tokens for LLM consumption
Retrieval and compression happen in shared continuous embedding space
Generator operates on compressed semantic vectors, not raw text
32-64× compression achieved while preserving answer-relevant information
Three-Stage Training Pipeline
Stage 1 - Compression Pretraining:
Train document compressor using QA pairs and paraphrases
Objective: Compress documents while retaining information needed to answer questions
Supervision via Semantic Content Preservation (SCP)—synthetic data ensuring compressed vectors support QA
Stage 2 - Instruction Tuning:
Fine-tune compressor for downstream question-answering tasks
Specializes compression for specific domains or question types
Adapter-based approach enables domain customization without full retraining
Stage 3 - End-to-End Joint Optimization:
Train retrieval reranker and answer generator jointly
Single language modeling loss with gradients flowing through both modules
Differentiable top-k estimator enables integrated ranking
Result: Retrieval relevance aligned with answer quality (not independent objectives)
Flexible Compression Rates
CLaRa supports 1× to 256× compression, enabling deployment tradeoffs:
Low compression (4-8×): Maximum accuracy for quality-critical applications
Medium compression (32-64×): Production sweet spot balancing accuracy and efficiency
High compression (128-256×): Maximum throughput for cost-sensitive deployments
Performance Results
Benchmark Validation
Evaluated on four multi-hop question-answering datasets:
Natural Questions
HotpotQA
MuSiQue
2WikiMultiHopQA
vs. PISCO baseline (state-of-the-art text-based RAG):
Normal retrieval: +1.13% average improvement
Oracle retrieval: +5.35% average improvement
“Often surpassing text-based fine-tuned baselines”
Key finding: Compressed continuous representations outperform full text, not just match it.
Efficiency Gains
32-64× document compression translates to:
Context window reduction: 10,000 tokens → 150-300 tokens for same knowledge
Inference cost: ~50× reduction in processing cost (quadratic attention)
Throughput: Process 30-50× more queries in same time budget
Memory: 32-64× smaller KV cache for retrieved knowledge
Strategic Implications
When CLaRa Changes Economics
Cloud RAG deployments:
Context token pricing ($0.25-2.00 per 1M tokens) makes long-context retrieval expensive
50× cost reduction per query = viability of RAG for price-sensitive applications
Enables retrieval from 100s of documents (previously limited to 5-10 by cost)
Edge RAG deployments:
Mobile devices limited to 4-8K context windows
64× compression enables retrieval-augmented intelligence on smartphones
Privacy-preserving RAG without cloud dependencies becomes viable
Enterprise knowledge bases:
Legal, medical, financial domains require retrieval from extensive corpora
Current RAG limited by context costs; CLaRa enables comprehensive retrieval
Single query can access 100+ compressed documents vs. 5-10 full text
Deployment Considerations
Ideal use cases:
High-volume RAG where context costs dominate (customer support, documentation search)
Multi-document reasoning requiring synthesis from many sources
Edge deployments where context window constraints limit RAG viability
Cost-sensitive applications where per-query economics matter
Implementation requirements:
Three pre-trained models available (Base, Instruct, End-to-End) via Hugging Face
PyTorch ≥2.0, Transformers ≥4.20, DeepSpeed ≥0.18
OpenRLHF framework for distributed training
Flash Attention 2 support for efficiency
Not suitable for:
Simple factoid QA where single-document retrieval suffices
Scenarios where compression training data unavailable
Applications requiring perfect fidelity (legal citations, code generation)
Paradigm Shift: Compression-Native Architecture
CLaRa represents more than incremental improvement—it’s a fundamental rethinking of RAG:
Old paradigm:
Retrieval optimized for document relevance (BM25, dense embeddings)
Generation optimized for answer quality (LLM fine-tuning)
Independent objectives connected by text concatenation
New paradigm:
Retrieval and generation jointly optimized in shared continuous space
Compression preserves answer-critical information (not document similarity)
Unified objective: Maximize answer quality from compressed knowledge
Strategic consequence: Organizations treating retrieval and generation as separate systems (different teams, different optimization cycles) will underperform competitors with end-to-end architectures.
Open-Source Release
Apple has released CLaRa as open-source:
Models: Hugging Face (CLaRa-7B-Base, Instruct, E2E)
Training code: Full pipeline including multi-stage training
Evaluation scripts: Benchmark reproduction on four QA datasets
Documentation: Jupyter notebooks, example data, requirements
Significance: Major tech companies (Google, Meta, Microsoft) have kept advanced RAG techniques proprietary. Apple’s open release accelerates ecosystem adoption.
Deep Dive Available
Comprehensive technical analysis covering:
Continuous latent reasoning framework architecture
Semantic Content Preservation training methodology
End-to-end joint optimization mechanics
Compression-accuracy tradeoff analysis
Deployment strategies for cloud and edge
Production integration considerations
Read: 2025-11-27 CLaRa - Compression-Native RAG Deep Dive
About SAINTS Special Editions
SAINTS special editions provide deep technical analysis of landmark papers that warrant dedicated examination. Edition 04x focuses on CLaRa due to its fundamental reconception of retrieval-augmented generation and immediate deployment applicability through open-source release.
Regular SAINTS editions: Weekly analysis of 5-6 critical papers in efficient AI
Special editions: Single-paper deep dives for breakthrough techniques
About SAINTS
Small AI Intelligence Service delivers strategic analysis of breakthroughs in efficient AI systems. Each edition identifies critical research advances and translates technical innovations into deployment implications for practitioners building production AI systems.
Focus areas: Model compression, hardware acceleration, efficient architectures, edge deployment, quantization, knowledge distillation, and neural architecture search.
Publication schedule: Weekly editions every Monday, with occasional special editions for landmark papers.
Next Regular Edition: December 08, 2025 (Week 49 papers)
Current Special Edition: CLaRa - Apple’s Compression-Native RAG