

For years, the 1-bit LLM was a thought experiment. Papers proved it was theoretically possible. Small prototypes demonstrated the mechanics. But nobody had trained one from scratch, at meaningful scale, on enough data to know whether native 1-bit weights could produce a model you’d actually want to use.
On April 8, 2026, Microsoft Research released BitNet b1.58 2B4T: a 2-billion parameter language model with ternary weights ({-1, 0, +1}), trained natively on 4 trillion tokens. Open-source. Weights on Hugging Face. Inference code for GPU and CPU.
The benchmarks are not the point. The benchmarks are good --- competitive with LLaMA 3.2 1B, Gemma-3 1B, Qwen2.5 1.5B, SmolLM2 1.7B, and MiniCPM 2B across 16 tasks spanning language understanding, reasoning, math, coding, and conversation. BitNet wins outright on ARC-Challenge, ARC-Easy, PIQA, WinoGrande, BoolQ, and GSM8K. It averages 54.19 across all benchmarks, second only to Qwen2.5 1.5B (55.23) --- a model that requires 6.5x more memory.
But the benchmarks are not the point. The point is the existence proof: a model trained entirely in 1-bit, at scale, on a serious data budget, produces serious results. The hypothesis has been tested. The debate is over.
What “Native 1-Bit” Actually Means
BitNet b1.58 is not a full-precision model that has been compressed after training. It is a model that was born in ternary.
Every standard linear layer in the Transformer is replaced with a BitLinear layer. During the forward pass, weights are quantized to 1.58 bits via absolute-mean quantization, mapping them to {-1, 0, +1}. Activations are quantized to 8-bit integers using absolute-max quantization, applied per-token. The architecture is otherwise a standard Transformer with RoPE position embeddings, bias removal, and one notable swap: squared ReLU replaces SwiGLU in the feed-forward network, a choice that improves sparsity characteristics under ternary constraints.
The distinction from post-training quantization (PTQ) matters enormously. PTQ methods like GPTQ and AWQ take a model trained in full precision and compress it afterward. The model’s internal representations were learned in a 16-bit world; quantization is damage control. Native 1-bit training means the model learns its representations within the ternary constraint from the first gradient step. The representations it finds are ones that work in 1-bit, not ones that survive compression to 1-bit.
Table 2 of the paper makes this concrete. Qwen2.5 1.5B in full precision averages 55.72 on MMLU/GSM8K/IFEval. Apply GPTQ INT4 quantization and it drops to 52.15 --- a 3.6-point loss. Apply AWQ INT4 and it drops to 51.17. BitNet b1.58 2B4T, at roughly half the memory of the INT4 models (0.4GB vs 0.7GB), scores 55.01. Native 1-bit training at 2B parameters with 4T tokens outperforms post-training quantization of a stronger base model at 4x the bit-width.
The Training Recipe
The training process followed three stages: large-scale pre-training, supervised fine-tuning (SFT), and direct preference optimization (DPO). Each stage required adaptations for the 1-bit paradigm.
Pre-training used a two-stage learning rate schedule. Stage 1 employed a high peak learning rate --- higher than typical full-precision training --- because 1-bit models exhibit greater training stability. The ternary weight constraint acts as an implicit regularizer, allowing more aggressive learning. Stage 2 was a cooldown phase at significantly lower learning rate, coinciding with a shift to higher-quality data. Weight decay followed a complementary schedule: cosine to 0.1 during Stage 1, then disabled entirely in Stage 2 to allow parameters to settle.
The pre-training corpus included DCLM (web crawl), FineWeb-EDU (educational pages), and synthetic mathematical data. Total: 4 trillion tokens. By comparison, LLaMA 3.2 1B was trained on 9 trillion tokens (via pruning and distillation from a larger model), and Qwen2.5 1.5B on 18 trillion tokens. BitNet achieved competitive performance with substantially less data --- the ternary constraint may force more efficient learning.
Supervised fine-tuning used WildChat, LMSYS-Chat-1M, WizardLM Evol-Instruct, SlimOrca, and synthetic datasets. A key finding: the model benefited from a larger learning rate during SFT than full-precision models of similar size, and required more epochs to converge. The 1-bit weight space has different optimization geometry.
DPO used UltraFeedback and MagPie preference data, trained for 2 epochs at learning rate 2×10⁻⁷. The team noted that DPO effectively steered the model toward preferred response styles without degrading core capabilities.
Notably absent: reinforcement learning via PPO or GRPO. The team explicitly flags this as future work. The model’s reasoning performance (GSM8K: 58.38, MATH-500: 43.40) was achieved without RL-based reasoning enhancement --- a strong baseline for what native 1-bit can do with standard training.
The Efficiency Numbers
The headline metrics for a CPU laptop deployment (Surface Laptop Studio 2, Intel i7-13800H, 8 threads):

Memory: 3.5x to 12x less than competitors. Latency: 1.4x to 4.3x faster. Energy: 6.6x to 23.2x less.
The energy number deserves emphasis. At 0.028 joules per token versus 0.258 J for LLaMA 3.2, BitNet uses 9.2x less energy for competitive or better performance. For battery-powered devices, this is the difference between a model that drains your phone in 20 minutes and one that runs all day.
The 1-Bit Landscape: BitNet vs. the Field
Table 3 compares BitNet b1.58 2B4T against every other publicly available 1-bit or near-1-bit model:
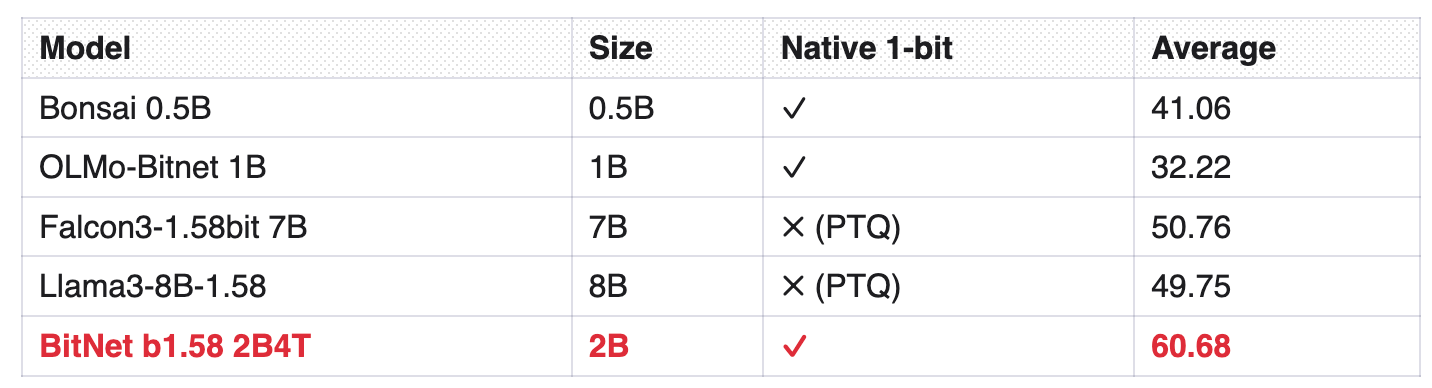
BitNet at 2B parameters outperforms Falcon3 at 7B and Llama3 at 8B --- both of which are full-precision models quantized to 1.58-bit after training. A native 1-bit model one-quarter the size beats PTQ models 3-4x larger. This is the strongest evidence yet that native training produces representations fundamentally better suited to extreme quantization than post-hoc compression.
The gap with Bonsai 0.5B and OLMo-Bitnet 1B is enormous (60.68 vs 41.06 and 32.22). These models were trained at smaller scale with less data. BitNet’s advantage is not just architectural --- it is the 4T-token data budget that allows a 1-bit model to develop rich representations despite the precision constraint.
The Kernel Problem
BitNet’s inference implementation reveals the current infrastructure gap. Standard GPU libraries (cuBLAS, PyTorch) have no optimized kernels for W1.58A8 (1.58-bit weights, 8-bit activations) matrix multiplication. The team built custom CUDA kernels that pack four ternary weight values into a single int8, store them in HBM, unpack in SRAM, then compute. This works, but the team is candid: “current commodity GPU architectures are not optimally designed for the 1-bit models.”
For CPU, the team built bitnet.cpp, a dedicated C++ inference library. It delivers the 29ms/token latency numbers above, outperforming llama.cpp on full-precision models despite the architectural mismatch.
The infrastructure message is clear: 1-bit models are production-ready in terms of model quality. The inference stack is functional but not yet optimized. Future hardware with native ternary logic could unlock another order-of-magnitude improvement.
Future Directions the Team Flags
Microsoft Research is transparent about what comes next:
Scaling: Can native 1-bit training work at 7B, 13B, and beyond? This is the open question. The paper’s results prove 2B. Whether the approach scales is unresolved.
Hardware co-design: Dedicated 1-bit accelerators could deliver “orders-of-magnitude improvements in speed and energy efficiency.”
Extended context: The current model’s context window is limited. KV-cache at 8-bit activations grows linearly with sequence length --- the same problem TurboQuant addresses from a different angle.
Reinforcement learning: No PPO/GRPO was used. Adding RL-based reasoning training to a 1-bit base model is an obvious next step.
Multimodal: 1-bit principles applied to vision-language models.
Why This Paper Matters for SAINTS Readers
BitNet b1.58 2B4T is not the best model at 2B parameters. It is the most efficient model at 2B-class performance. For SAINTS readers tracking edge deployment, the implications are:
The on-device threshold has shifted. A model competitive with Qwen2.5 1.5B now fits in 400MB. That’s an Apple Watch-class memory footprint with laptop-class capability.
Native training beats post-training compression. The gap between BitNet 2B and Falcon3-1.58bit 7B (native vs. PTQ, smaller vs. larger) settles a debate that has persisted since the first BitNet paper. If you’re planning a 1-bit deployment, start 1-bit --- don’t train big and compress down.
The training recipe is public. Two-stage learning rate, ternary weight constraint, standard SFT/DPO. No secret sauce. Any team with compute access can replicate this approach.
The scaling question is now the question. Everything about this model works at 2B. The paper’s own future directions section leads with “larger models.” If native 1-bit scales to 7-13B with proportional results, the entire inference cost structure of the industry changes. Edition 26-17 will examine why this scaling question remains open --- and what might answer it.
Sources:
Ma, S. et al. “BitNet b1.58 2B4T Technical Report.” Microsoft Research, April 2026. arXiv:2504.12285
Model weights: huggingface.co/microsoft/bitnet-b1.58-2B-4T
Inference code: github.com/microsoft/BitNet