
The Inference Stack Is the Product
SAINTS Intelligence Brief | Edition 26-13 | Special Edition, Part 3 of 3

“Is NVIDIA becoming a model company?”
This is a question that surfaces in every analyst call, every conference hallway, every Slack channel where infrastructure people argue about strategy. Twenty-plus model variants in eighteen months. Hybrid architectures no one else is shipping. Open-weight releases with commercial licenses. A synthetic data pipeline that produced 98% of its own alignment data. If you squint, it looks like NVIDIA is trying to become the next Meta AI or Mistral.
They are not. They are doing something more interesting --- and, for competitors, more dangerous.
NVIDIA is not building a model company. It is building an inference company. The models are not the product. The models are a component in a vertical stack designed to make NVIDIA silicon the default path from training to deployment. The stack is the product. And once you see the stack as a single system rather than a collection of parts, the strategic logic of every Nemotron release becomes obvious.
The Five Layers
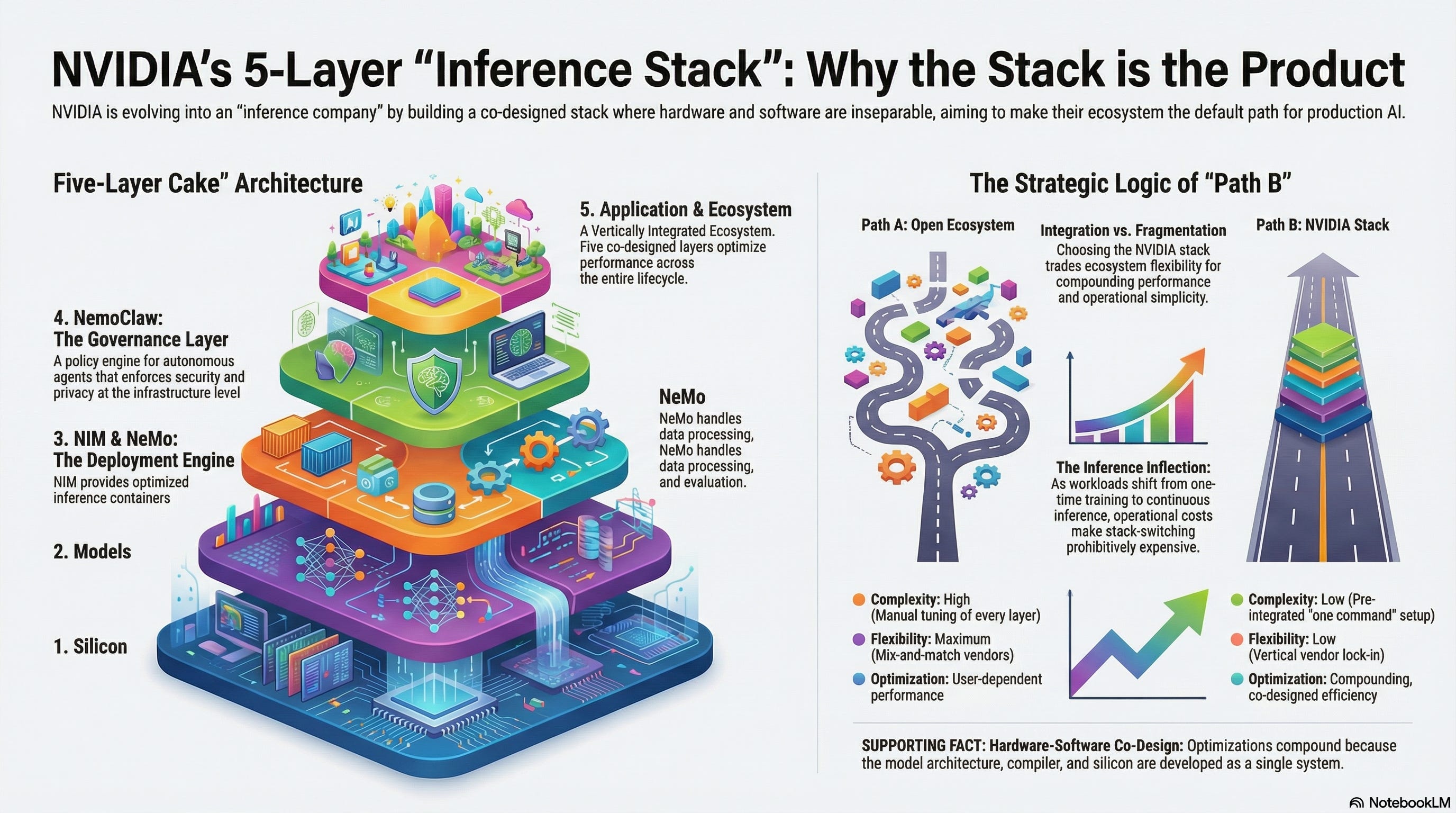
Jensen Huang has been describing NVIDIA’s strategy as a “five-layer cake” since late 2025. The framing is corporate, but the architecture is real.
Layer 1: Silicon. GPUs (Blackwell B200, the upcoming Rubin), the Vera CPU (88-core ARM), the recently acquired Groq LPU for ultra-low-latency inference, BlueField DPU for networking, and Jetson for edge. This is the layer everyone knows. It is also, increasingly, the layer NVIDIA treats as necessary but not sufficient.
Layer 2: Models. Nemotron for language and reasoning. Cosmos for world models and vision. Isaac GR00T for robotics. BioNeMo for biology and chemistry. Earth-2 for weather and climate. These are not vanity projects. Each model family is optimized to run on NVIDIA hardware through the next layer.
Layer 3: NIM (NVIDIA Inference Microservices). Prebuilt, optimized inference containers. Pull a NIM container, deploy on any NVIDIA-accelerated infrastructure. The container bundles the model, TensorRT-LLM optimizations, OpenAI-compatible APIs, and auto-scaling logic. NIM is the delivery mechanism that turns a model release into a deployable service. It also creates lock-in: NIM containers are optimized for NVIDIA silicon in ways that generic serving frameworks are not.
Layer 4: NeMo. The build-and-customize layer. NeMo Curator for data processing. NeMo Data Designer for synthetic dataset generation. NeMo Customizer for fine-tuning (LoRA, SFT, DPO, GRPO). NeMo Evaluator for benchmarking. NeMo Retriever for document extraction. NeMo Guardrails for safety. NeMo RL for reinforcement learning. This is the full model lifecycle --- data, training, evaluation, alignment, safety --- packaged as microservices. If NIM is how you deploy a model, NeMo is how you make it yours.
Layer 5: NemoClaw. The newest and most strategically revealing layer. Announced at GTC 2026, NemoClaw wraps the open-source agentic AI platform with enterprise security, privacy, and governance controls. An open-source runtime enforces policy-based privacy and security guardrails for autonomous agents. A privacy router determines what stays local versus what reaches the cloud. Local Nemotron models run on-device for privacy-sensitive workloads. Huang called the policy engine “potentially the policy engine of all the SaaS companies in the world.” The claim is premature. The strategic intent is not.
Install NemoClaw: one command. It pulls Nemotron models, configures NIM for local inference, sets up policy routing, and gives you an enterprise-grade agentic AI stack running on your own hardware. The stack --- from silicon to agent governance --- is NVIDIA’s, end to end.
Why the Stack Matters More Than the Model
Two paths for deploying a small AI model in production today.
Path A (Open ecosystem): Choose a model (Llama, Qwen, Mistral). Choose a serving framework (vLLM, TGI, Ollama). Choose quantization (GPTQ, AWQ, GGUF). Choose hardware (NVIDIA, AMD, Apple Silicon, CPU). Tune each layer for your specific combination. Debug incompatibilities. Optimize. Ship. Every layer is a separate decision with separate maintenance burden.
Path B (NVIDIA stack): Choose a Nemotron model. Deploy via NIM. Customize via NeMo. Govern via NemoClaw. Every layer is co-designed. Optimizations compound across layers because the model architecture, the compiler, the runtime, and the hardware were developed together. You give up choice. You gain integration.
Path A gives you flexibility and avoids vendor lock-in. Path B gives you performance and operational simplicity. For enterprises already running on NVIDIA GPUs --- which is most of them --- the marginal cost of choosing Path B is low, and the integration benefit is high. This is the strategic logic of the Nemotron program. Not “build a better model than Llama.” Build a stack where choosing our model is the obvious default for anyone already on our hardware.
The inference inflection makes this more powerful, not less. When training was the dominant workload, hardware lock-in was time-bounded --- you rented GPUs for a training run and moved on. Inference is continuous. Once your production workload runs on NIM-served Nemotron models on NVIDIA GPUs, the switching cost is not a one-time migration. It is ongoing operational disruption. Every month of inference deepens the commitment.
NemoClaw and the Governance Layer
NemoClaw reveals where NVIDIA thinks the value will accumulate.
The open-source agentic AI ecosystem has a trust problem. Misconfigured instances are exposed to the internet. Agent frameworks execute arbitrary tool calls without policy enforcement. Privacy boundaries are defined in application code, not infrastructure. The security story is “be careful,” which is not a security story.
NemoClaw addresses this with infrastructure-level controls: network guardrails, a privacy router that enforces data residency policy, and local model inference via Nemotron for workloads that cannot leave the device. This is not a feature. It is a positioning play. If NVIDIA succeeds in making NemoClaw the default governance layer for enterprise agentic AI, they own the policy surface --- the control plane through which all agent actions flow. The model underneath becomes interchangeable. The governance layer does not.
This is the mature version of the Nemotron strategy. In the early phase, the model sells the hardware. In the middle phase, the stack sells the model. In the mature phase, the governance layer sells the stack. Each layer creates lock-in for the layers below it.
What This Means for the SAINTS Thesis
SAINTS monitors ten categories of techniques that enable AI in constrained environments: quantization, pruning, distillation, low-rank methods, efficient architectures, sparse activation, compiler optimization, hardware-software co-design, edge deployment, and hybrid approaches.
NVIDIA’s Nemotron program touches eight of the ten. The Mamba-2 hybrid is an efficient architecture. The Latent MoE is sparse activation. NVFP4 is quantization. The Elastic Framework is pruning and distillation. TensorRT-LLM is compiler optimization. NIM on Jetson is edge deployment. The entire program is hardware-software co-design. And the combination of Mamba-2 with MoE and latent routing is a hybrid approach.
NVIDIA is not publishing these as research papers and waiting for adoption. They are shipping them as production components of an integrated stack. The gap between “research technique published on arXiv” and “shipping in production” --- the gap SAINTS has tracked across twelve editions --- is closing. And it is closing fastest inside vertically integrated stacks where the same organization controls the research, the implementation, and the deployment target.
For the small AI field, the implication is structural: the era of model-as-independent-artifact may be ending. When the chip company builds the model, the runtime, the customization tools, and the governance layer, the “best model” question becomes “best model for this stack.” The benchmark leaderboard fragments along infrastructure lines. The universal comparison table --- MMLU, GSM8K, HumanEval, may the best model win --- assumes a neutral playing field that is becoming less neutral by the quarter.
This does not mean open models lose their value. Llama’s ecosystem, Qwen’s multilingual breadth, Phi’s parameter efficiency, Gemma’s TPU optimization, Mistral’s licensing freedom --- these are real advantages that serve real needs. But the competitive frame is shifting from “which model is best” to “which stack is best for my infrastructure.” NVIDIA has spent eighteen months and twenty-plus model releases engineering their answer to that question.
For Your Next Conversation
Evaluate stacks, not just models. If your organization runs production inference on NVIDIA GPUs, evaluate NIM-served Nemotron against your current model-plus-serving setup as a system, not as a model swap. The integration benefits --- TensorRT-LLM optimization, auto-scaling, OpenAI-compatible APIs --- compound. A benchmark comparison that isolates the model from its runtime understates the difference.
Watch the governance layer. NemoClaw is early, but the strategic logic is clear: whoever controls the policy surface for enterprise agentic AI controls the stack beneath it. If your organization is building agentic workflows, evaluate governance solutions now --- before the default becomes someone else’s. The cost of switching governance layers after deployment is higher than switching models.
The inference inflection changes your cost model. Training costs are one-time and bounded. Inference costs are continuous, variable, and scale with usage. If your planning assumes training-era economics, recalculate. Cost per token on your deployed infrastructure --- not benchmark accuracy on a leaderboard --- is the metric that will determine which AI investments generate returns. NVIDIA has built an entire company strategy around this shift. Whether you use their stack or not, the shift is real.
Series Summary

The bottom line: NVIDIA is not competing on models. It is competing on the system that makes models deployable, affordable, and governable on NVIDIA hardware. The models are the bait. The stack is the trap. And the inference inflection --- the structural shift from training-dominated to inference-dominated compute --- is the tide that makes the trap work.
Whether this is good or bad for the industry depends on your position. If you are building on NVIDIA hardware, the stack reduces friction and cost. If you are building alternatives to NVIDIA hardware, the stack is the moat you have to cross. Either way, it is the most consequential strategic move in the small AI landscape since Meta open-sourced Llama.
Edition 26-13, Part 3 of 3 | SAINTS Intelligence Brief
Previous: The Chip Company’s Model Lab | Good Enough to Be Dangerous
smallaimodel.substack.com